Context-free grammar is a more powerful method to describe languages. Such grammars can describe certain features that have a recursive structure, which is useful in various of applications. And context-free grammars were first to used in the study of human languages, which include many terms, such as noun, verb, preposition. Because while understanding their relationships and their respective phrases, it will lead to the natural recursion. Context-free grammars have the ability to capture these important patterns of the relationships among these languages. The collection of languages associated with context-free grammars are called the context-free languages. The grammar is often used in the parser, which is contained in the compiler and interpreter for programming languages to extract the meanings of a program in advance of generating the complied code or performing the interpreted execution. Applying the context-free grammars, we can construct the parser for the programming languages. In this article I will introduce the concepts of Context-free languages and program a syntax analyzer for SL for practicing. Besides, I will introduce Pushdown Automata, which is a class of powerful machines to recognize context-free languages.
Reference:
- Introduction to the theory of computation —Michael. Sipser
- Teaching Materials in the course of System Programming — Zili Shao.
Context-free Grammars
If you try to use regular expressions to describe the language L = {a^nb^n, n>=0}, you will soon find it impossible. Because the pattern of counting the same numbers of alphabets can not be performed by regular expressions. However, this pattern is quite commonly used in human’s communicating and understanding of languages, therefore, we need another more powerful grammars.
This is an example of context-free languages, and it describes the language L = {a^nb^n, n>=0}.
A grammar consists of a collection of substitution rules, also called productions. Each rule appears line by line, comprising a symbol and a string separated by an arrow. The symbol is called a variable. The string consists of variables and other symbols is called terminals. Usually, the symbol variable is represented by the capital letters, and the terminals are represented by lowercase letters, numbers and special symbols. One variable in these rules is called start variable, which is the left-most symbol of the top-most rule.
Take the grammar above for an example, S is its start variable, another variable is T, and its terminals are a and b.
When we use this grammar to generate a string, say string ‘aaabbb’, the process will be as follow:
This process is called derivation. Step by step, we replace the symbol on the left-hand side with terminals according to the rules, and derive the string from the one another, finally when there is no more symbols in the string, there is it.
Formal Description for CFG
A context-free grammar is a 4-tuple (V, ∑, R, S), where
- V is a finite set of variables.
- ∑ is a finite set of terminals, disjoint from V.
- R is a finite set of rules, which turn the variables into the terminals.
- S ⊆ V is the start variable.
Take the formal grammar as example, its context-free grammar is ({S, T}, {a, b}, R, S), where R is
Parsing Tree
Consider there is a context-free grammar G1 ({
With this grammar, we can generate strings, say a+a×a and (a+a)×a as follow:
- a+a×a
|
|
- (a+a)× a
|
|
The process could be drawn as the parsing tree.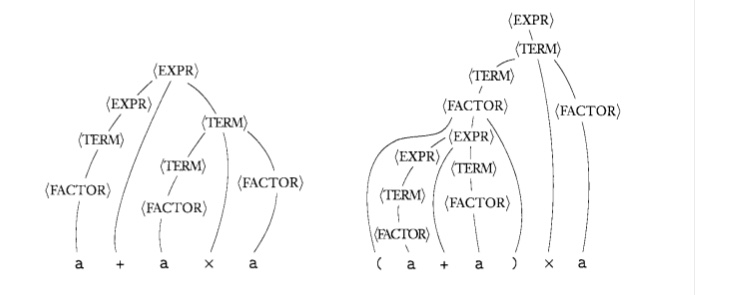
A compiler is a specific program to translate the code written in programming language into another form, which is more suitable for execution. Therefore, the compiler’t job is to extracting the meaning of the code to be compiled in a process called parsing.
One way of representing the parsing process is to draw a parsing tree for the code, in the context-free grammar for the programming language.
Syntax Analyzer
In the practice part of context-free language, I implemented a syntax analyzer utilizing the recursive descent parser for the SL on the context-free grammar (for its lexical analyzer part, please see : Simple Language ). The syntax analyzer can parse the program segment and judge if it could be accepted according to its context-free grammar.
The context-free grammar is as follow:
Notice that this grammar has no right-recursion, which avoids the endless loop in the process of parsing.
Now let’s add the token name into this grammar for reference. In order to shorten the written job, I simply replace the token name with a single alphabet as a symbol.
| Token Name | Symbol |
|---|---|
| KEYWORD var | A |
| KEYWORD begin | a |
| KEYWORD end | b |
| PLUS | F |
| MINUS | G |
| COMMA | B |
| DIV | I |
| SEMICOLON | C |
| LBRACE | J |
| ASSIGN | D |
| RBRACE | K |
| PERIOD | E |
| ID | L |
| NUM | M |
| Unrecognized | N |
Then the grammar will look like this:
R
So the grammar can be written formally as G({PROG, PROG_BODY, ID_LIST, STATEMENT_LIST, ID_LIST’, STATEMENT, STATEMENT’, EXP, TERM, E’, FAC, T’}, {A, a, b, B, C, D, E, F, G, H, I, J, K, L, M}, R, {PROG}).
Implement
Firstly, I continued using the scan() part in the lexical analyzer for extract the tokens in the program segment.
After it gets the tokens and translate them into a string of symbols, it uses the string as the input and the point p can help to locate the symbols. Finally, it starts doing the parsing job with the code below:
Using recursion, the code will be so concise and easy to understand, that the variable could be treated as a function could be called in itself, and the terminals are detected as an alphabet as the string.
And in the main, it opens the input_file and execute these lines to process both the lexical and the syntax analyses.
Conclusion
Let’s test it with an example:
Example 1:
The result: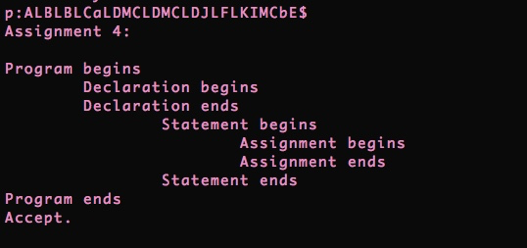
Let’s test a negative example with the syntax error:
Example 2:
It misses a ‘;’ after ‘5’
The result: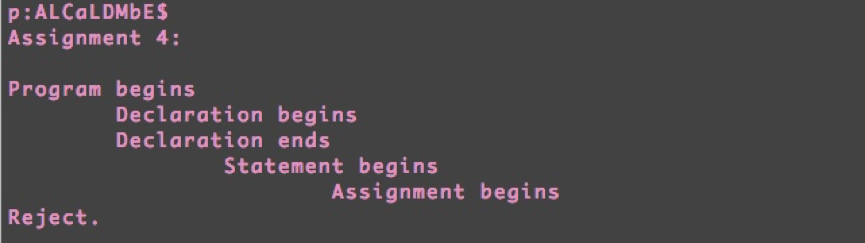
All in all, I have to say this practice sample is just my personal version of implementation, so there must be some things could be revised and improved. I just wrote them down in case the situation I need to find and keep them in mind.
This is the end of my review article, feel free to contact with me if you have any problem with my article.