
Among all of the computational models, Finite Automata is the simplest one, however, it plays an important role in the development of computers. Nowadays, though computers are much more complicated and powerful, Finite Automata still lies the heart of many electromechanical devices. This article is a review of my learning process and my ideas during the implementation practice of a simple Lexical Analyzer applying the Finite Automata.
Reference:
- Introduction to the theory of computation —Michael. Sipser
- Teaching Materials in the course of System Programming — Zili Shao.
Finite Automata
Finite Automata is math model to make decision according to the terminal states which can be approached by reading the input strings and consequently making transitions of the states according to both the current state and input.
Here is a simple Finite Automata M1 which recognizes all strings on 0,1 ending up with a 1. The figure is called the state diagram of it.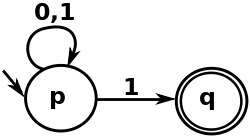
To understand this figure, we need some definitions on these notations. There are mainly two components, the circles and the arrows with alphabets on them. The first circle represents a start state because there is an empty arrow pointing it, and the second one with double circles represents the accept state. Then, obviously, these arrows with alphabets on them represent the transitions from one state to the next, and it will transit only when the currently inputting part hits on these alphabets. To fully understand it, we need to try a specific strings and put them in, let’s say 1101. See what will happen step by step. Imagine that you are standing in front of this Finite Automata, and now you are in the start state p. According to the input strings 1101, the working process will be as follow:
You are in state p, and you get the first number 1. Look at the round arrow above state p, it means that if you get a 1 or 0, the next state could be p again. So you will still in p after reading the first 1. Actually, there is a little trick here, notice that the other arrow with 1 also means that when receiving a 1, you could go to the state q. So here comes to the idea of Nondeterministic Finite Automata, which means that the different transitions will happen even resulting from a same input. In other words, the decision-making is not deterministic, there exists some multiple choices, and it depends on some specific situations such as the following parts of the input. For example in this case, though receiving a 1, you may follow the round arrow above to continue working the FA but not the straight one pointing to an accept state directly because you are still holding with the rest alphabets of string.
Then is another 1. Similarly, you will go back to p according to the round arrow.
- Then is a 0. Notice that the round arrow also says that when receiving a 0, you should go to p again. So you are still in p after reading this 0.
- Finally, the last one is a 1. This time, you don’t have any other following alphabets, so you can choose the straight arrow and go through it, and you will go to the state q.
- After reading all of the string, you are now on the state q, and it is an accept state, so this we call this string is accepted by this FA.
DFA and NFA
Deterministic Finite Automata is a kind of Finite Automata that allows no uncertainty in the transitions. To be more specific, it doesn’t allow the distinctive arrows with same transition conditions(normally it is the alphabet) on one state, also it doesn’t include the empty string ‘ε’ to be served as the transition condition. Besides, every alphabet should has its transition in each state. Apparently, the FA I just introduced is not a Deterministic Finite Automata, therefore, it is a Nondeterministic Finite Automata, which allows the uncertainty.
The empty string ‘ε’ means that without any condition the transition can be done as long as it is staying in that state. From a state q, all states that can be approached by ε are called the ε-closure of q.
Finite Automata is a good model for computers with a limited memory. For example, the automatic door is a kind of electromechanical devices controlled by the Finite Automaton.
Formal Definition
The formal definition of a Finite Automata is a tuple contains five components, writes ( Q, ∑, δ, q0, F).
- Q is a finite set called the states.
- ∑ is a finite set called the alphabet.
- δ = Q × ∑ -> Q is the transition function.
- q0 is the start state.
F ⊆ Q is a set of accept states.
Take the M1 just mentioned as example. Let’t use this formal definition to describe it:
Q = {p, q}
∑ = {0,1}
δ is :
| p | q | |
|---|---|---|
| 0 | p | ∅ |
| 1 | p, q | ∅ |
q0 = p
F = {q}
Regular Language
If a set A is the set of all strings that can be accepted by a Finite Automata M, we call this set the regular language of Finite Automata M, writes L(M) = A.
A machine may recognize several strings, but it only recognize one language.
Furthermore, a language is called regular language if some finite automata recognize it.
Regular Operation
There are three operations can be exerted on Languages. They are Union, Concatenation, Star.
- Union: A ∪ B = {x| x ⊆ A or x ⊆ B}.
- Concatenation : A∘B = {x y| x ⊆ A and y ⊆ B}.
- Star: A∗ = {x1x2x3x4….x k|k≥0, and each xi ⊆ A}.
Regular Expressions
Since we already get both the idea of regular language and regular operations, now we use these regular operations to describe the languages, which are called regular expressions.
For example,
(0∪1)*1
is a regular expression, which describes the language that starts with several 0s and 1s and ending up with a 1. The first part
(0∪1)*
means to “star” the union of {1} and {0}, which is to contain any number of the strings in {1} or {0}. The second part means the first part to concatenate with a 1, here we have omitted a concatenation symbol ∘.
Regular Expression is very useful in the applications of computer science, as we use it to express the pattern of strings. For example, a programming language could use it for the mechanism to describe the patterns of the tokens such as the key words, and this mechanism to recognize the tokens in the language can be called a lexical analyzer.
Practice
Here is the practice from my course “System Programming”.
Write a program (a lexical analyzer) with C or Java Program Language for SL based on the FA. For tokens with the types ID, KEYWORD and NUM, you should give the lexeme (value) of the token (see the sample output as an example).
SL is a simple language, The following is a sample program with SL.
The sample test program:
In SL, a program begins with the declaration for variables using the keyword “var” following variable names. The program segment starts with the keyword “begin” and ends with the keyword “end” and “.”. A program segment consists of statements. A statement has two cases: (1) It can be another program segment; (2) It can be an assignment statement consisting of identifiers, “=” and expressions. An expression consists of number (integer and real number), operators (+,-, , /). For numbers, you only need to consider integer and real number. For operators, you only need to consider +, -, , and /. For all other symbols that are not defined can be reported as “Unrecognized” and in any case, your program should be able to finish to scan all inputs.
The syntactic elements and their corresponding tokens are listed as follows:
| Syntactic Element | Token Name |
|---|---|
| var | KEYWORD |
| begin | KEYWORD |
| + | PLUS |
| - | MINUS |
| end | KEYWORD |
| * | MUL |
| , | COMMA |
| / | DIV |
| ; | SEMICOLON |
| ( | LBRACE |
| = | ASSIGN |
| ) | RBRACE |
| . | PERIOD |
| Integer (e.g. 124) or real number (e.g. 1.2) | NUM |
| A string starting with letter and following with letter or digit | ID |
Design a lexical analyzer
- Regular Expression for the tokens
VAR -> var
BEGIN -> begin
END -> end
KEYWORD -> VAR| BEGIN| END
PLUS -> +
MINUS -> -
COMMA -> ,
DIV -> /
SEMICOLON -> ;
LBRACE -> (
ASSIGN -> =
RBRACE -> )
PERIOD -> .
LETTER -> a|b|c|d|….|z|A|B|C|D|…..|Z
DIGIT -> 1|2|3|4|5|6|7|8|9|0
ID -> LETTER(LETTER|DIGIT)
INTEGER -> DIGIT(DIGIT)
NUM -> INTEGER(.|ℇ) INTEGER
- Finite Automata to recognize SL
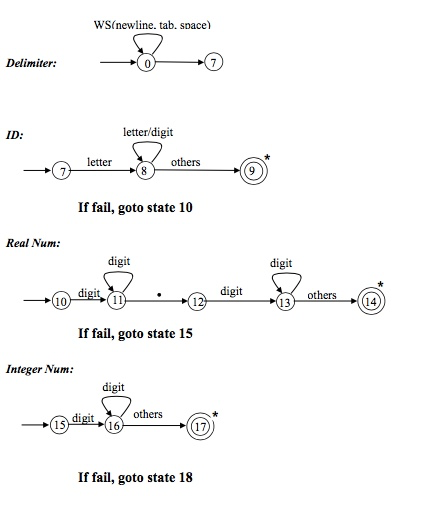
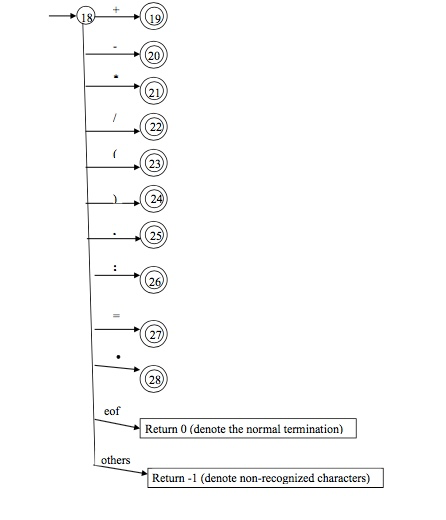
Implementation
I wrote three functions besides the main function to complete the analysis job.
They are respectively scan(), get_next_token() and print_token(). And here is some heading definitions and global variables of my program.
The scan() function is to open the input file and take charge of making decision about moving the start point or terminating the prorcess while looping function get_next_token().
|
|
The key function is the get_next_token(), in this function I implemented the finite automata by using the mechanism of “cases-switch” to represent each state.
BTW, I wrote a function named isMember(), which can be commonly used.
|
|
|
|
After that, I wrote a function print_token() which takes in the token number and value and then prints its name and token value into a certain format.
Finally, the main function, which opens the input_file, and calls the scan() function to run.
But this rest part of functions are omitted since they are not related to the process of the finite automata.
This output sample looks like this:
The sample SL:
The output: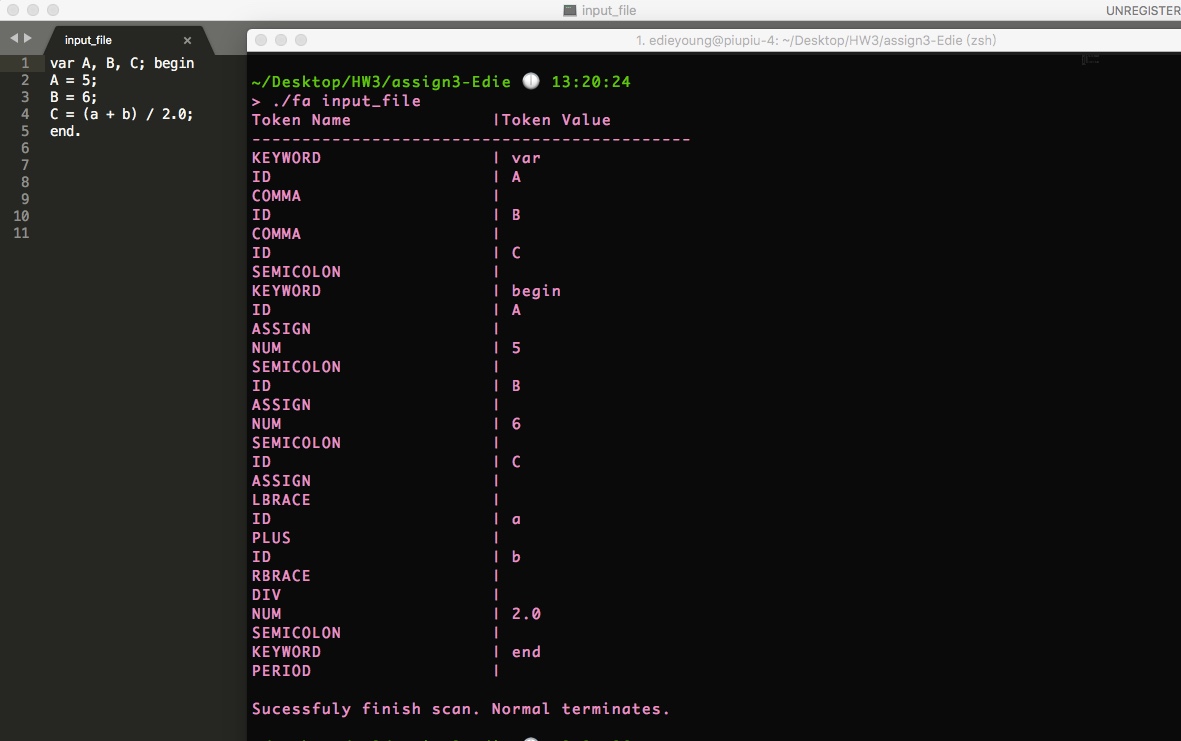
Conclusion
Here is the end of my review article about Finite Automata and Lexical Analyzer homework, hope it can help. Thanks for reading.